우리나라의 산업통계는 2017년부터 KSIC 10차 개정을 쓰고 있다. 그런데 2017년 이전 통계도 쓸 일이 있다 보니 9차 개정을 쓸 일이 있는데 R에서 쓸 수 있는 분류표가 없어서 따로 만들기로 했다.
통계분류포털(kssc.kostat.go.kr) 들어가서 한국표준산업분류>자료실>최신개정 들어가면 제9차 한국표준산업분류 분류항목표라는게 있고 KSIC2007.xls라는 파일을 받을 수 있다. 엑셀로 열어보면 대략 이렇다.

대-중-소-세-세세분류가 하나로 합쳐져 있다. tidy한 데이터가 없는 것이 좀 아쉽긴 한데, 그래도 이 엑셀 파일은 인쇄해서 윗사람에게 바로 보여줄 수도 있고, 약간의 가공을 거치면 R에서도 쓸 수 있으니 통계청은 상당히 효율적으로 일을 한 것이다. 이제부터 R에서 쓸 수 있는 파일로 가공을 하려고 한다.
먼저, 엑셀 파일을 부른다. 여러 방법이 있는데 readxl 패키지의 read_excel() 함수를 썼다. 이 함수는 header=F 같은 옵션을 쓸 수 없는 대신 col_names= 옵션을 써서 변수 이름을 정해 주면 첫 줄이 변수 이름이 되는 걸 막을 수 있다.
install.packages("readxl")
library(readxl)
ksic9<-read_excel("KSIC2007.xls",col_names=c("code","name_ko","name_en"))결과를 보면,
> head(ksic9)
# A tibble: 6 x 3
code name_ko name_en
<chr> <chr> <chr>
1 "A 농업, 임업 및 어업 (01 ~ 03)\nAgriculture, forestry and fishing" NA NA
2 NA NA NA
3 "01" 농업 Agriculture
4 NA NA NA
5 "011" 작물 재배업 Growing of Crops
6 NA엑셀 파일도 그랬지만 불러진 데이터는 한줄씩 띄우기가 되어 있으니 빈 줄을 삭제한다. code 변수 값이 NA인 행을 삭제하는 명령을 준다.
ksic91<-ksic9[which(!is.na(ksic9$code)),]첫 줄에 A로 시작하는 이름이 대분류명이다. 엑셀 파일을 스크롤해서 내려보면 알겠지만 나중에 B로 시작하는 두번째 대분류가 나오고 그럴 것이다. code 변수의 첫글자를 일단 딴다. 만약 대분류라면 알파벳 대문자일 것이고 중-소-세-세세분류라면 숫자일 것이다. 옳게 된 대분류 코드가 나오면 그대로 유지하고 숫자가 나오면 위에 옳게 된 대분류 코드로 대체하면 된다.
ksic91$code_a<-substr(ksic91$code,1,1)
for(i in 1:nrow(ksic91)){
if(grepl("[A-Z]",ksic91[i,]$code_a)) temp<-ksic91[i,]$code_a
else ksic91[i,]$code_a<-temp
}substr(string, a, b) 함수는 string 문자열 변수의 a번째부터 b번째까지의 글자를 반환한다. 위의 코드는 code 변수의 첫번째 한글자만 뽑아서 code_a 변수에 넣은 것이다. grepl() 함수는 문자열 안에 특정 문자열이 포함되어 있으면 TRUE를 반환하는 함수인데, 여기서 "[A-Z]"는 정규표현식으로, "대문자 A부터 대문자 Z까지 사이의 글자 중 아무 글자"라는 뜻이다. 즉 code_a 변수에 알파벳 대문자가 있으면 temp 변수에 그 대문자를 저장하고 만약 없으면 temp가 저장하고 있는 알파벳 대문자로 code_a 변수의 값을 대체하는 것으로, 모든 산업명에 대분류 코드를 집어 넣는다.
> ksic91<-ksic91[,c("code","code_a","name_ko","name_en")]
> head(ksic91)
# A tibble: 6 x 4
code code_a name_ko name_en
<chr> <chr> <chr> <chr>
1 "A 농업, 임업 및 어업 (01 ~ 03)\nAgricul~ A NA NA
2 "01" A 농업 Agriculture
3 "011" A 작물 재배업 Growing of Crops
4 "0111" A 곡물 및 기타 식량작~ Growing of Cereal Crops and Other Crops f~
5 "01110" A 곡물 및 기타 식량작~ Growing of Cereal Crops and Other Crops f~
6 "0112" A 채소, 화훼작물 및 ~ Growing of Vegetables, Horticultural Spec~
> tail(ksic91)
# A tibble: 6 x 4
code code_a name_ko name_en
<chr> <chr> <chr> <chr>
1 "U 국제 및 외국기관(99)\nActivities of extraterrito~ U NA NA
2 "99" U 국제 및 외국기~ Extra-Territorial Organizations and~
3 "990" U 국제 및 외국기~ Extra-Territorial Organizations and~
4 "9900" U 국제 및 외국기~ Extra-Territorial Organizations and~
5 "99001" U 주한 외국공관 Foreign Embassies
6 "99009" U 기타 국제 및 ~ Other Extra-Territorial Organizatio~code_a라는 변수에 A부터 U까지의 대분류 코드가 잘 들어갔다. 보시다시피 대분류는 전부 21개이다. 대분류만 따로 모아서 별도의 표를 만든다.
ksic92<-data.frame(ksic91[grep("^[A-Z]",ksic91$code),1])grep() 함수는 문자열 변수에 특정 문자열이 포함된 행의 번호를 반환한다. 정규표현식에서 앞에 ^ 표시는 "뒤에 나오는 글자로 시작하는"이란 뜻이다. 즉 "^[A-Z]"는 "알파벳 대문자로 시작하는"이란 뜻이다. 일단 첫줄만 볼 거 같으면,
> ksic92[1,]
[1] "A 농업, 임업 및 어업 (01 ~ 03)\nAgriculture, forestry and fishing"대분류 코드로 시작하고 한글명, (중분류 코드 범위), 영문명 이렇게 들어가 있다. 잘보면 영문명 앞에 줄바꿈표 '\n'가 들어가 있는데 이걸 이용해서 문자열을 한국어와 영어로 분리한다. strsplit() 함수를 쓰면 사이에 낀 문자열을 기준으로 문자열을 둘로 분리할 수 있는데, 리스트로 만들어준다. 두 개의 변수로 된 데이터프레임으로 만들려면 다음과 같은 짓을 해야 한다.
1) unlist() : 리스트를 뽀개서 문자열로 만든다. 한국어명과 영어명이 하나씩 번갈아가며 나오는 문자열 배열이 된다.
2) matrix() : 한줄로 된 배열을 2 by 21 행렬로 변환한다.
3) t() : transpose 명령으로 행과 열을 맞바꿔 21 by 2 행렬이 된다.
4) data.frame() : matrix를 data.frame으로 변환한다.
ksic921<-strsplit(ksic92[,1],"\n")
ksic922<-unlist(ksic921)
ksic923<-t(matrix(ksic922,2,21))
ksic924<-data.frame(ksic923)ksic924 데이터의 결과를 보면 이렇다.
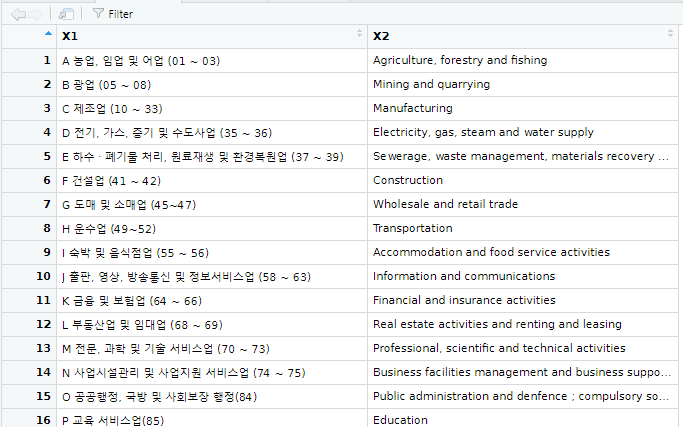
이제 원하는 글자들을 뜯어서 각각 코드명, 한국어명, 영어명으로 된 대분류표를 만들 수 있다. 다 만들었으니 csv 파일로 저장까지 하자.
code_a<-substr(ksic924$X1,1,1)
name_a_ko<-substr(ksic924$X1,3,100)
name_a_en<-ksic924$X2
ksic9a<-data.frame(code_a,name_a_ko,name_a_en)
write.csv(ksic9a,"ksic9a.csv")완성된 대분류표이다. 변수 이름에 a를 집어 넣은 건 이게 대분류이기 때문이고 앞으로 중분류, 소분류를 계속 만들것이기 때문이다.

이제 중분류를 만들어 보자. 아까 만들었던 데이터로 돌아가야 한다. ksic91에서 code가 알파벳 대문자로 시작하는 것만 따로 모아서 대분류를 만들었는데, 이제는 code가 알파벳 대문자로 시작하지 않는 것만 따로 모은다. 여기서 또 헷갈리는 정규표현식 문법이 하나 등장한다. "^[A-Z]"라고 쓰면 "A-Z 사이의 문자 중 하나로 시작하는"인데, "^[^A-Z]"라고 쓰면 "A-Z 사이의 문자가 아닌 문자 중 하나로 시작하는"이란 뜻이 된다.(^ 표시는 [] 밖에 있을 때랑 안에 있을 때 다른 뜻으로 쓰인다.)
ksic93<-data.frame(ksic91[grep("^[^A-Z]",ksic91$code),])결과를 열어 보면,

code를 보면 두자리부터 다섯자리까지 다양한데, 이제부터 편하다. 앞에 두 자리는 무조건 중분류, 한자리 더 붙여서 세자리면 소분류, ... 이렇게 세세분류까지 가니까 하나씩 뜯어서 중-소-세-세세분류를 만들면 된다.
ksic93$code_b<-substr(ksic93$code,1,2)
ksic93$code_c<-substr(ksic93$code,1,3)
ksic93$code_d<-substr(ksic93$code,1,4)
ksic93$code_e<-substr(ksic93$code,1,5)
ksic93<-ksic93[,c("code_a","code_b","code_c","code_d","code_e","code","name_ko","name_en")]요렇게 나온다.
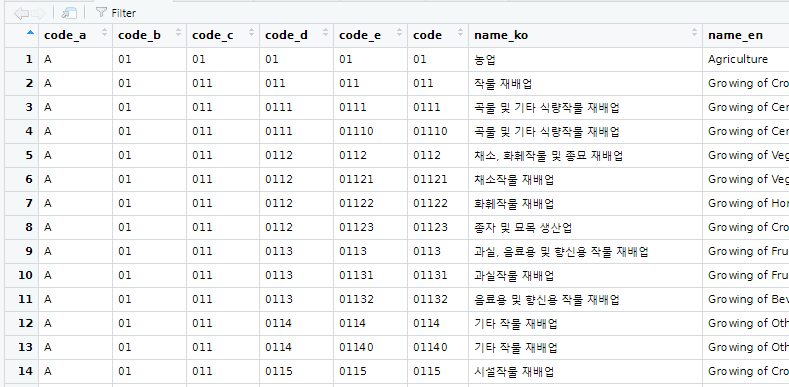
이제 code 변수를 기준으로 데이터를 추출해 중분류표, 소분류표, 세분류표, 세세분류표를 만들 수 있게 되었다. 모든 분류표는 상위분류도 갖고 있으니 얼마나 좋은가. code 변수의 글자수(자릿수)를 기준으로 두자리면 중분류표로 보내고 세자리면 소분류표로 보내고... 하면 된다. 표 분리를 하고 나면 이젠 code 변수는 필요 없으니 처치한다.
ksic9b<-ksic93[which(nchar(ksic93$code)==2),c("code_a","code_b","name_ko","name_en")]
names(ksic9b)<-c("code_a","code_b","name_b_ko","name_b_en")
ksic9c<-ksic93[which(nchar(ksic93$code)==3),c("code_a","code_b","code_c","name_ko","name_en")]
names(ksic9c)<-c("code_a","code_b","code_c","name_c_ko","name_c_en")
ksic9d<-subset(ksic93[which(nchar(ksic93$code)==4),],select=-c(code_e,code))
names(ksic9d)<-c("code_a","code_b","code_c","code_d","name_d_ko","name_d_en")
ksic9e<-subset(ksic93[which(nchar(ksic93$code)==5),],select=-code)
names(ksic9e)<-c("code_a","code_b","code_c","code_d","code_e","name_e_ko","name_e_en")중분류표인 ksic9b만 일단 살펴보자.

상위 분류인 대분류 코드를 갖고 있는데, 만일 대분류 산업명을 붙이고 싶으면 이미 만들어놓은 대분류표가 있으니 merge() 함수를 이용해 붙이면 된다.
ksic9ba<-merge(x=ksic9a,y=ksic9b,key=code_a,all.y=T)[,c("code_a","name_a_ko","code_b","name_b_ko")]결과를 보자.

소스의 풀버전은 여기(https://github.com/jujaeuk/KSIC-9-)에서 받을 수 있다.
'R' 카테고리의 다른 글
| R, split() - factor 값을 기준으로 데이터 분할하기 (0) | 2019.09.16 |
|---|---|
| R, apply, lapply, sapply, tapply (0) | 2019.09.15 |
| R, ggplot2 - 그래프 예쁘게 그려주는 라이브러리 (0) | 2018.07.12 |
| R, pdf 문서에서 텍스트 추출하기 (Xpdf) (0) | 2018.06.22 |
| R, data sorting하기 order() (0) | 2018.05.21 |